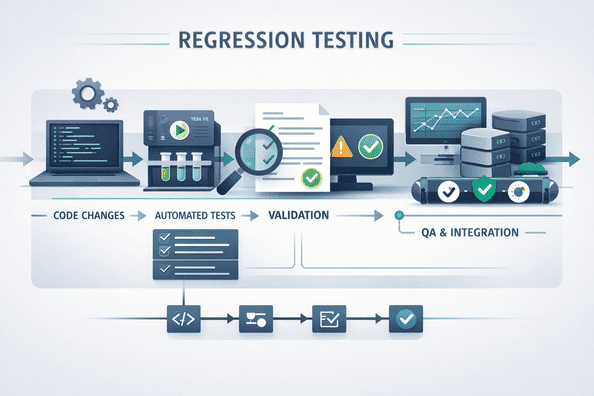
Modern systems rarely stay stable for long. APIs evolve to support new features, data schemas are updated to handle new requirements, and services change independently in distributed architectures. While this flexibility is necessary, it also introduces a constant risk of breaking existing functionality.
This is where automated regression testing becomes essential. Its role is not just to verify that the system works today, but to ensure that ongoing changes do not silently break what already works.
Why Changing APIs and Data Create Challenges
APIs and data structures form the foundation of system communication. When they change, even slightly, the impact can be wide.
Common challenges include:
- Modified request and response formats
- Renamed or removed fields
- Changes in data types or validation rules
- Backward compatibility issues
- Inconsistent handling across services
These changes may not immediately cause visible failures, but they often introduce subtle issues that surface later.
The Limitations of Static Testing Approaches
Traditional regression testing relies on predefined test cases and fixed data. This approach works well for stable systems but struggles in dynamic environments.
Problems include:
- Tests becoming outdated as APIs evolve
- Missing coverage for new or modified fields
- Increased maintenance effort
- False confidence from passing outdated tests
Without continuous updates, test suites lose their effectiveness over time.
How Automated Regression Testing Adapts to Change
To remain useful in systems with changing APIs and data, automated regression testing must be flexible and adaptive.
1. Validating API Contracts Continuously
APIs act as contracts between services. Automated tests help ensure that these contracts remain intact.
Teams can:
- Validate response structures and required fields
- Check for unexpected changes in output
- Detect breaking changes early
This prevents issues from spreading across dependent services.
2. Supporting Backward Compatibility
Maintaining compatibility with existing consumers is critical.
Automated regression testing helps by:
- Testing older API versions alongside new ones
- Ensuring existing clients continue to function
- Identifying regressions introduced by updates
This reduces the risk of breaking integrations.
3. Handling Schema Evolution
Data schemas evolve as systems grow.
Automated tests can:
- Validate both old and new data formats
- Detect mismatches in data types
- Identify missing or unexpected fields
This ensures that data changes do not disrupt system behavior.
4. Focusing on Behavior Instead of Structure
Rigid tests that depend on exact data structures tend to break easily.
A better approach is to:
- Focus on expected outcomes
- Validate critical fields rather than entire payloads
- Allow flexibility where appropriate
This makes tests more resilient to change.
5. Updating Tests as Part of the Development Process
Test maintenance should not be an afterthought.
Teams should:
- Update test cases alongside code changes
- Review test coverage when APIs evolve
- Remove outdated or redundant tests
This keeps the test suite aligned with the system.
6. Using Realistic Data and Scenarios
Synthetic data often fails to capture real-world complexity.
Automated regression testing becomes more effective when it includes:
- Realistic input data
- Actual usage patterns
- Edge cases derived from production behavior
Some teams address this by capturing real API interactions and turning them into test cases. Tools like Keploy support this approach by generating tests from actual system traffic. This helps ensure that tests remain relevant as APIs and data evolve.
7. Integrating with CI/CD Pipelines
Frequent changes require continuous validation.
Automated regression testing should:
- Run with every code change
- Provide immediate feedback
- Prevent breaking changes from reaching production
This ensures that issues are detected early.
Common Mistakes to Avoid
Even with automation, teams often face challenges due to common mistakes:
- Relying on outdated test cases
- Testing only happy paths
- Ignoring backward compatibility
- Over-validating entire responses instead of key fields
- Failing to update tests as APIs evolve
Avoiding these mistakes improves both efficiency and accuracy.
Real-World Perspective
In real systems, API and data changes are constant. Without proper regression testing, these changes can lead to:
- Broken integrations
- Data inconsistencies
- Unexpected system behavior
- Production incidents
Automated regression testing helps teams manage this complexity by continuously validating system behavior.
Teams that adopt adaptive testing practices:
- Detect issues earlier
- Reduce regression risks
- Maintain stability despite frequent changes
- Improve confidence in deployments
Practical Takeaways
To handle changing APIs and data effectively:
- Validate API contracts continuously
- Support backward compatibility
- Focus on behavior rather than rigid structures
- Use realistic data and scenarios
- Keep test suites updated
- Integrate testing into CI/CD pipelines
These practices help maintain reliable systems in dynamic environments.
Conclusion
Changing APIs and evolving data schemas are a reality of modern software development. Static testing approaches cannot keep up with this pace.
Automated regression testing provides a scalable way to ensure that systems remain stable as they evolve. By focusing on flexibility, real-world behavior, and continuous validation, teams can reduce the risk of hidden issues and deliver reliable software even in rapidly changing environments.